45 keras reuters dataset labels
Python keras.datasets.reuters.load_data() Examples def load_retures_keras(): from keras.preprocessing.text import tokenizer from keras.datasets import reuters max_words = 1000 print('loading data...') (x, y), (_, _) = reuters.load_data(num_words=max_words, test_split=0.) print(len(x), 'train sequences') num_classes = np.max(y) + 1 print(num_classes, 'classes') print('vectorizing sequence … Keras for R - RStudio The dataset also includes labels for each image, telling us which digit it is. For example, the labels for the above images are 5, 0, 4, and 1. Preparing the Data. The MNIST dataset is included with Keras and can be accessed using the dataset_mnist() function. Here we load the dataset then create variables for our test and training data:
Parse UCI reuters 21578 dataset into Keras dataset · GitHub Share Copy sharable link for this gist. Clone via HTTPS Clone with Git or checkout with SVN using the repository's web address. Learn more about clone URLs. Download ZIP. Parse UCI reuters 21578 dataset into Keras dataset. Raw.

Keras reuters dataset labels
Datasets - Keras Documentation - faroit Fraction of the dataset to be used as test data. This dataset also makes available the word index used for encoding the sequences: word_index = reuters.get_word_index (path= "reuters_word_index.pkl" ) Return: A dictionary where key are words (str) and values are indexes (integer). eg. word_index ["giraffe"] might return 1234. Where can I find topics of reuters dataset · Issue #12072 · keras-team ... In Reuters dataset, there are 11228 instances while in the dataset's webpage there are 21578. Even in the reference paper there are more than 11228 examples after pruning. Unfortunately, there is no information about the Reuters dataset in Keras documentation. Is it possible to clarify how this dataset gathered and what the topics labels are? TensorFlow - tf.keras.datasets.reuters.load_data - Loads the Reuters ... This is a dataset of 11,228 newswires from Reuters, labeled over 46 topics. This was originally generated by parsing and preprocessing the classic Reuters-21578 dataset, but the preprocessing code is no longer packaged with Keras. See this github discussion for more info. Each newswire is encoded as a list of word indexes (integers).
Keras reuters dataset labels. Reuters newswire classification dataset - Keras This is a dataset of 11,228 newswires from Reuters, labeled over 46 topics. This was originally generated by parsing and preprocessing the classic Reuters-21578 dataset, but the preprocessing code is no longer packaged with Keras. See this github discussion for more info. Each newswire is encoded as a list of word indexes (integers). What is keras datasets? | classification and arguments - EDUCBA Reuters classification dataset for newswire is somewhat like IMDB sentiment dataset irrespective of the fact Reuters dataset interacts with the newswire. It can consider dataset up to 11,228 newswires from Reuters with labels up to 46 topics. It also works in parsing and processing format. # Fashion MNIST dataset (alternative to MNIST) Datasets in Keras - GeeksforGeeks Keras is a python library which is widely used for training deep learning models. One of the common problems in deep learning is finding the proper dataset for developing models. In this article, we will see the list of popular datasets which are already incorporated in the keras.datasets module. MNIST (Classification of 10 digits): Is there a dictionary for labels in keras.reuters.datasets? I managed to get an AI running that predicts the classes of the reuters newswire dataset. However, I am desperately looking for a way to convert my predictions (intgers) to topics. There has to be a dictionary -like the reuters.get_word_index for the training data- that has 46 entries and links each integer to its topic (string). Thanks for ...
Datasets - Keras Datasets The tf.keras.datasets module provide a few toy datasets (already-vectorized, in Numpy format) that can be used for debugging a model or creating simple code examples. If you are looking for larger & more useful ready-to-use datasets, take a look at TensorFlow Datasets. Available datasets MNIST digits classification dataset keras source: R/datasets.R - R Package Documentation the class labels are: #' #' * 0 - t-shirt/top #' * 1 - trouser #' * 2 - pullover #' * 3 - dress #' * 4 - coat #' * 5 - sandal #' * 6 - shirt #' * 7 - sneaker #' * 8 - bag #' * 9 - ankle boot #' #' @family datasets #' #' @export dataset_fashion_mnist <- function () { dataset <- keras $ datasets $fashion_mnist$load_data() as_dataset_list (dataset) … Datasets - Keras Documentation - faroit keras.datasets.reuters Dataset of 11,228 newswires from Reuters, labeled over 46 topics. As with the IMDB dataset, each wire is encoded as a sequence of word indexes (same conventions). Usage: (X_train, y_train), (X_test, y_test) = reuters.load_data(path="reuters.pkl", \ nb_words=None, skip_top=0, maxlen=None, test_split=0.1, seed=113) NLP: Text Classification using Keras - E2E Cloud We have to import these datasets from Keras. After importing, its feature dataset and label dataset are individually stored in two tuples. Each tuple contains both training and testing portions. You can import Reuters dataset from Keras-20 NewsGroups- It is another dataset source, consisting of approx. 20,000 documents across 20 different topics.
TensorFlow - tf.keras.datasets.mnist.load_data - Loads the MNIST dataset. Loads the MNIST dataset. View aliases. Compat aliases for migration. See Migration guide for more details. tf.compat.v1.keras.datasets.mnist.load_data. tf.keras.datasets.mnist.load_data ( path= 'mnist.npz') This is a dataset of 60,000 28x28 grayscale images of the 10 digits, along with a test set of 10,000 images. Introduction to Keras, Part One: Data Loading - Medium Data labels is a 1D array specifying a label against every image. Using matplotlib library, you can show the images present in the dataset. Output Image by Author Image Generator An Image Generator class can be used to specify certain traits to the images in a dataset. Using the data_dir which you generated in section 2.2. The Reuters Dataset · Martin Thoma The Reuters Dataset · Martin Thoma The Reuters Dataset Reuters is a benchmark dataset for document classification . To be more precise, it is a multi-class (e.g. there are multiple classes), multi-label (e.g. each document can belong to many classes) dataset. It has 90 classes, 7769 training documents and 3019 testing documents . Datasets - keras-contrib IMDB Movie reviews sentiment classification. Dataset of 25,000 movies reviews from IMDB, labeled by sentiment (positive/negative). Reviews have been preprocessed, and each review is encoded as a sequence of word indexes (integers). For convenience, words are indexed by overall frequency in the dataset, so that for instance the integer "3" encodes the 3rd most frequent word in the data.
Custom Data Augmentation in Keras
Keras for Beginners: Implementing a Recurrent Neural Network Keras is a simple-to-use but powerful deep learning library for Python. In this post, we'll build a simple Recurrent Neural Network (RNN) and train it to solve a real problem with Keras.. This post is intended for complete beginners to Keras but does assume a basic background knowledge of RNNs.My introduction to Recurrent Neural Networks covers everything you need to know (and more) for this ...
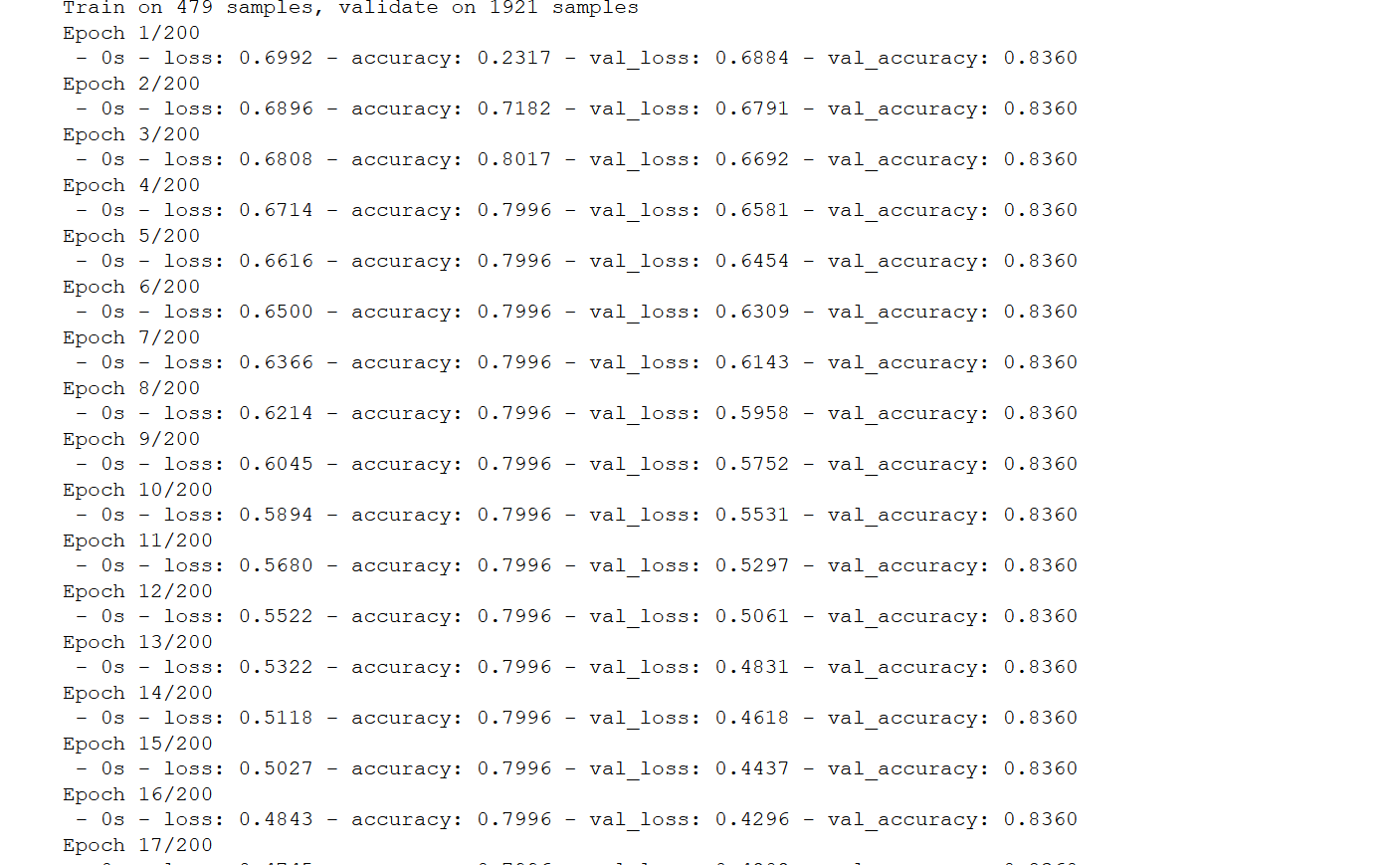
Fraud Detection using Keras
PDF Introduction to Keras - AIoT Lab from keras.utils import to_categorical trn_labels = to_categorical(train_labels) tst_labels = to_categorical(test_labels) ... Load the Reuters Dataset •Select 10,000 most frequently occurring words 42 from keras.datasets import reuters (train_data, train_labels), (test_data, test_labels) =

Custom Data Augmentation in Keras
Classifying Reuters Newswire Topics with Recurrent Neural Network The purpose of this blog is to discuss the use of recurrent neural networks for text classification on Reuters newswire topics. The dataset is available in the Keras database. It consists of 11,228...
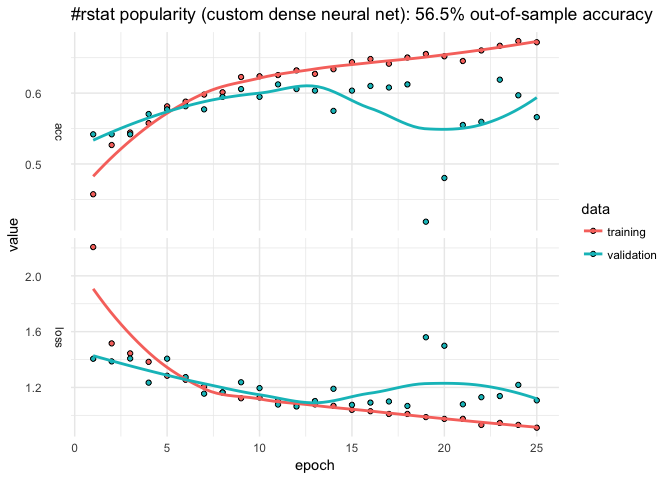
RStudio AI Blog: Analyzing rtweet Data with kerasformula
keras/reuters.py at master · keras-team/keras · GitHub This is a dataset of 11,228 newswires from Reuters, labeled over 46 topics. This was originally generated by parsing and preprocessing the classic Reuters-21578 dataset, but the preprocessing code is no longer packaged with Keras. See this [github discussion] ( ) for more info.

ImportError: cannot import name 'normalize_data_format' · Issue #298 · keras-team/keras-contrib ...
Text Classification in Keras (Part 1) — A Simple Reuters News ... The Code import keras from keras.datasets import reuters Using TensorFlow backend. (x_train, y_train), (x_test, y_test) = reuters.load_data (num_words=None, test_split=0.2) word_index = reuters.get_word_index (path="reuters_word_index.json") print ('# of Training Samples: {}'.format (len (x_train)))
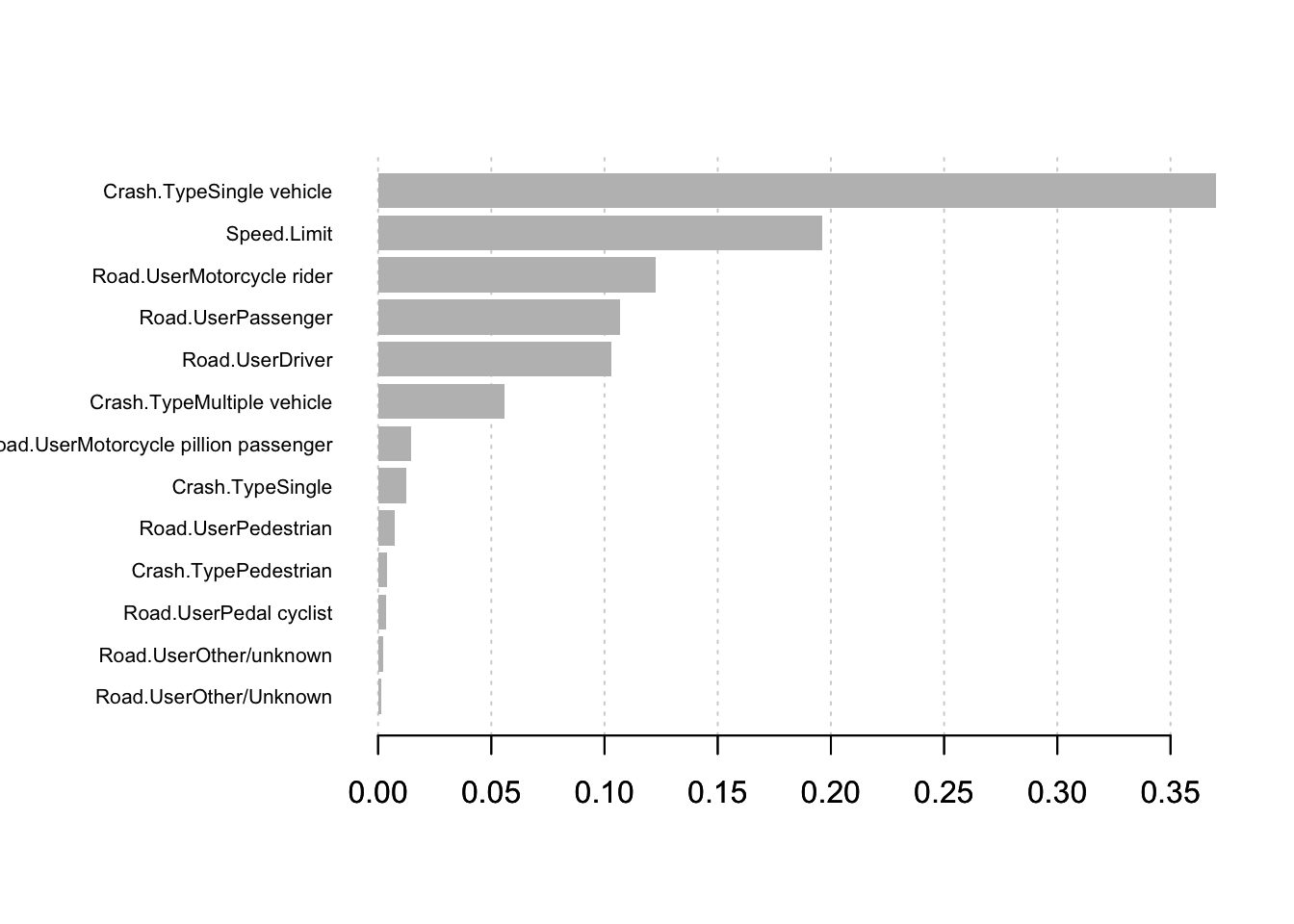
My top 10 R packages for data analytics - My top 10 R packages for data analytics | Actuaries ...
How to do multi-class multi-label classification for news categories Built a Keras model to do multi-class multi-label classification. Visualize the training result and make a prediction. ... This post we focus on the multi-class multi-label classification. Overview of the task. We are going to use the Reuters-21578 news dataset. With a given news, our task is to give it one or multiple tags. The dataset is ...
![[Keras] 뉴스 기사 토픽 분류로 보는 다중 분류(multi-classification)](https://img1.daumcdn.net/thumb/R800x0/?scode=mtistory2&fname=https:%2F%2Ft1.daumcdn.net%2Fcfile%2Ftistory%2F994BEC3D5C2354770B)
[Keras] 뉴스 기사 토픽 분류로 보는 다중 분류(multi-classification)
Tutorial On Keras Tokenizer For Text Classification in NLP To do this we will make use of the Reuters data set that can be directly imported from the Keras library or can be downloaded from Kaggle. This data set contains 11,228 newswires from Reuters having 46 topics as labels. We will make use of different modes present in Keras tokenizer and will build deep neural networks for classification.
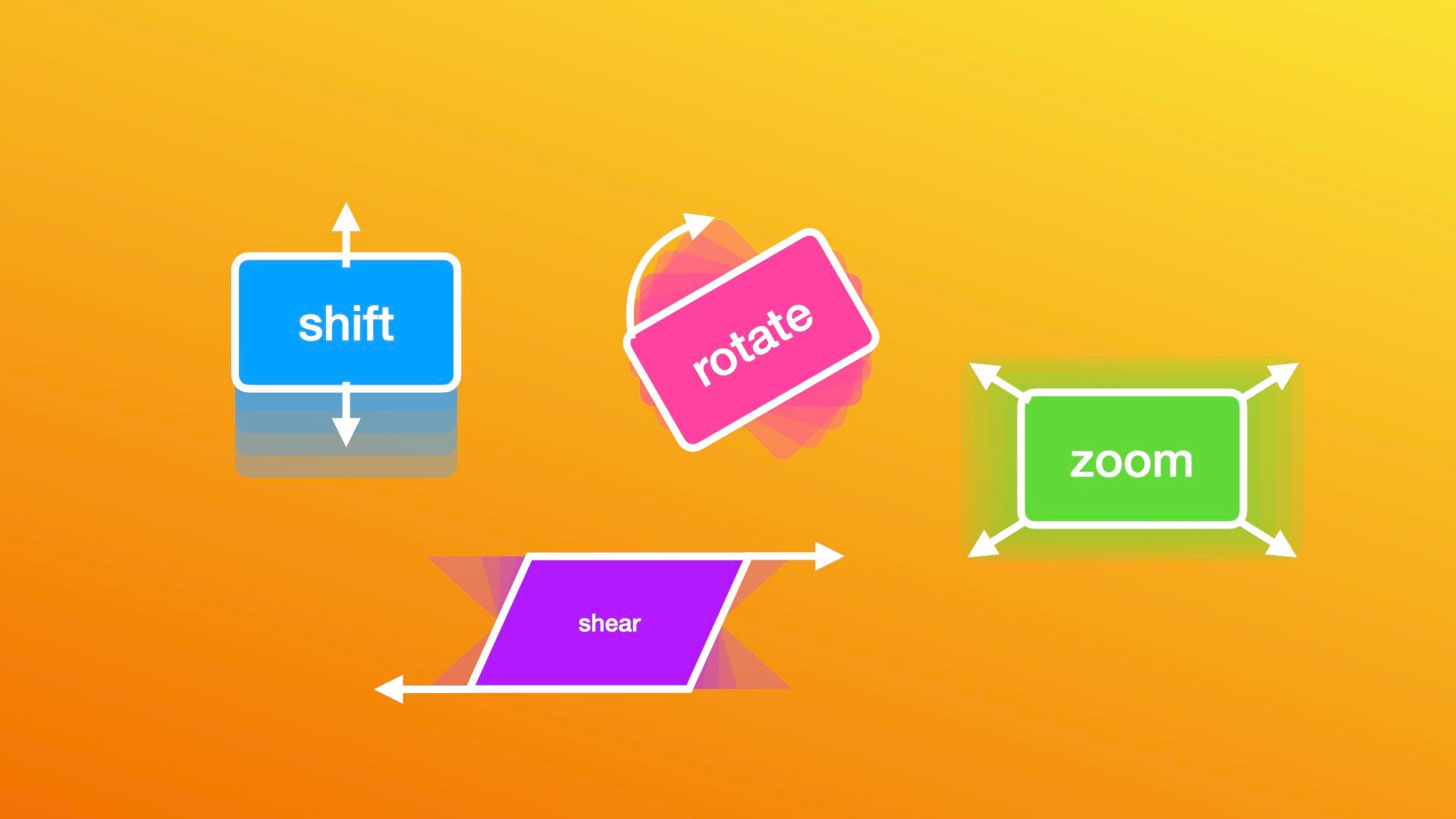
Image Data Augmentation Tutorial in Keras
Function reference • keras dataset_reuters() dataset_reuters_word_index() Reuters newswire topics classification. ... Generates batches of augmented/normalized data from image data and labels. flow_images_from_directory() ... Install TensorFlow and Keras, including all Python dependencies. is_keras_available() Check if Keras is Available.
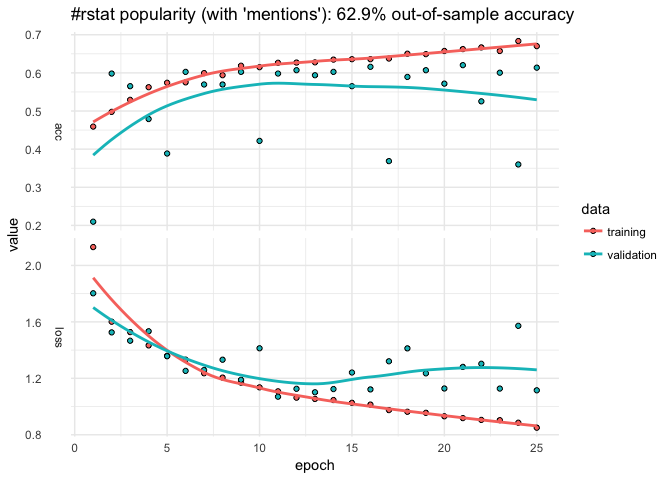
RStudio AI Blog: Analyzing rtweet Data with kerasformula
How to show topics of reuters dataset in Keras? - Stack Overflow Associated mapping of topic labels as per original Reuters Dataset with the topic indexes in Keras version is: ['cocoa','grain','veg-oil','earn','acq','wheat','copper ...
![[Get 38+] Image Generator Keras Flow](https://pyimagesearch.com/wp-content/uploads/2019/07/keras_data_augmentation_jitter.png)
[Get 38+] Image Generator Keras Flow
Namespace Keras.Datasets - GitHub Pages Dataset of 50,000 32x32 color training images, labeled over 100 categories, and 10,000 test images. Fashion MNIST Dataset of 60,000 28x28 grayscale images of 10 fashion categories, along with a test set of 10,000 images. This dataset can be used as a drop-in replacement for MNIST. The class labels are: IMDB
Nlp News Dataset - NLP Practicioner
TensorFlow - tf.keras.datasets.reuters.load_data - Loads the Reuters ... This is a dataset of 11,228 newswires from Reuters, labeled over 46 topics. This was originally generated by parsing and preprocessing the classic Reuters-21578 dataset, but the preprocessing code is no longer packaged with Keras. See this github discussion for more info. Each newswire is encoded as a list of word indexes (integers).
Post a Comment for "45 keras reuters dataset labels"